How Codynex Built a Production-Ready RAG Platform?
Case study - How Codynex engineered a production-ready RAG platform using hybrid search and smart optimization strategies

Retrieval Augmented Generation, commonly known as RAG, has become the holy grail for businesses wanting to use AI on their own private data. The concept sounds simple enough on paper:
- Take a user question.
- Search internal documents for the answer.
- Pass that information to an AI model to generate a response.
Building a basic Retrieval-Augmented Generation (RAG) system is surprisingly easy. It often takes less than 100 lines of code. However, moving that system into a production environment where accuracy, reliability, and speed are non-negotiable is where most projects fail.
This case study explores exactly how we engineered a solution that solves these common pitfalls.
Solving the "Garbage In, Garbage Out" Problem
The foundation of any RAG system is the data. If your data is poorly parsed or inconsistently chunked, your LLM will struggle to find the right answers. We implemented a sophisticated data pipeline that utilizes Recursive Character Splitting and metadata tagging to ensure that every chunk of information retains its original context.
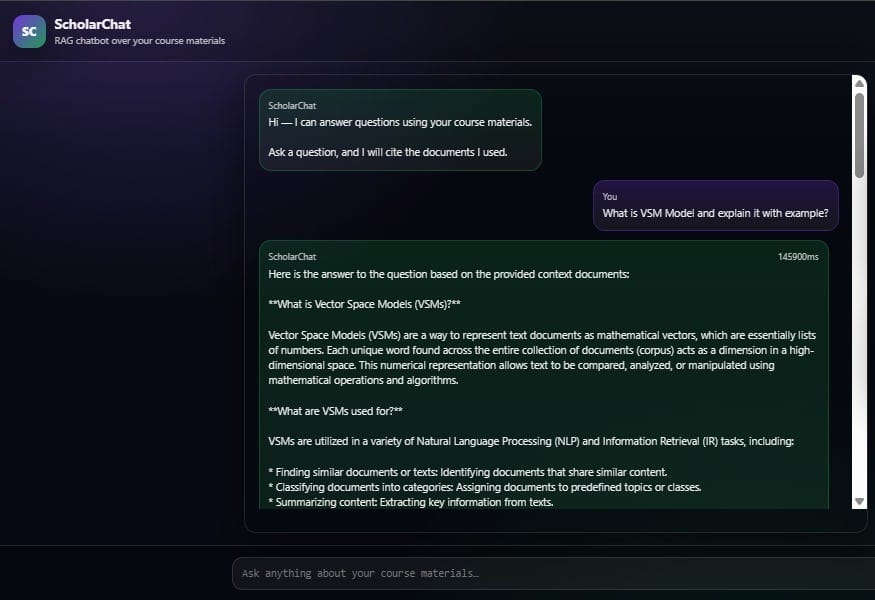
Why this matters for SEO and Authority:
As seen in the screenshot above, our platform does not just pull raw text; it structures the response. Notice how the system explains Vector Space Models (VSMs) by breaking down their mathematical purpose and practical use cases in NLP. This level of clarity is only possible when your retrieval engine, built on FAISS and E5 embeddings, is finely tuned to understand document hierarchy.
Precision Retrieval: Beyond Simple Vector Search
Standard vector search often lacks the precision needed for specific historical or technical queries. To reach production-grade status, we implemented Hybrid Search and Re-ranking.
When a user asks a question, our system does not just look for similar words. It evaluates the most relevant documents and re-ranks them using Cross-Encoders to ensure the top results are truly the most informative.
Verifiability: The "Citation" Standard
In an enterprise setting, an AI’s word is not enough. It needs proof. We built our platform with a citation-first philosophy. Every claim made by the AI must be backed by a specific source from the uploaded knowledge base.
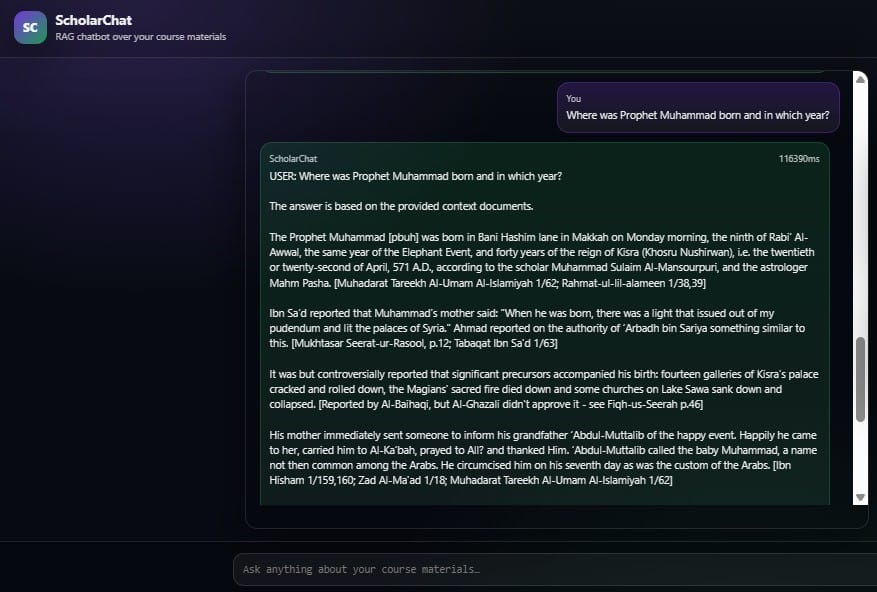
Technical Deep Dive: In the screenshot above, a complex question regarding the birth of Prophet Muhammad [pbuh] is answered. Notice the bracketed citations following every factual claim. This demonstrates our platform's ability to:
- Handle Multi-Domain Knowledge: The system seamlessly switches between technical NLP data and historical academic texts.
- Ensure Faithfulness: The AI explicitly states that the answer is based on the provided context documents, which prevents the model from hallucinating external information.
Optimized for Performance
Production environments demand speed. We optimized our platform to handle high-concurrency requests while maintaining low latency. As shown in our screenshots, even with deep retrieval across extensive datasets, such as Sealed Nectar or Cloud Computing course materials, the system delivers comprehensive, formatted responses in a matter of seconds.
Key Features of the RAG pipeline approach:
- FAISS and E5 Embeddings: These provide high-performance vector storage and retrieval.
- Context-Grounded Answers: This feature minimizes hallucinations by strictly adhering to provided materials.
- Multi-Domain Flexibility: The platform handles everything from technical engineering to academic history.
- Source Transparency: We have included built-in citations for every response.
The platform we built at Codynex now serves as the backbone for multiple client applications, handling thousands of queries with high precision and low latency. It proves that with the right engineering approach, AI can be trusted with your most private and complex business data.

Comments ()